要通过代码生成Rss订阅源,首先应该了解Rss订阅源到底是什么东西。
我们打开少数派官方提供给我们的Rss订阅源,保存网页可以看到Rss订阅源本质上就是一个储存在文件服务器里面的Xml文件。

打开xml文件,结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| <?xml version="1.0" encoding="UTF-8"?>
<rss
xmlns:atom="http://www.w3.org/2005/Atom"
xmlns:dc="http://purl.org/dc/elements/1.1/" version="2.0">
<channel>
<title>少数派</title>
<link>https://sspai.com</link>
<description>少数派致力于更好地运用数字产品或科学方法,帮助用户提升工作效率和生活品质</description>
<language>zh-CN</language>
<managingEditor>contact@sspai.com (少数派)</managingEditor>
<pubDate>Wed, 20 Apr 2022 17:26:49 +0800</pubDate>
<item>
<title>写给想用代码建造新世界的你</title>
<link>https://sspai.com/post/72729</link>
<description>摆在你面前的是一份诱惑:100 小时后,代码能让你成为一个新世界的主宰。
<a href="https://sspai.com/post/72729" target="_blank">查看全文</a>
</description>
<author>数字工具组</author>
<pubDate>Wed, 20 Apr 2022 17:26:49 +0800</pubDate>
</item>
<item>
<title>「干净又卫生」受人喜爱的原因,被我用 Python 爬出来了</title>
<link>https://sspai.com/post/72756</link>
<description>
<p>[......]</p>
<a href="https://sspai.com/post/72756" target="_blank">查看全文</a>
<p>本文为付费栏目文章,出自
<a href="https://sspai.com/series/271" target="_blank">《100 小时后请叫我程序员》</a >,订阅后可阅读全文。
</p >
</description>
<author>100gle</author>
<pubDate>Wed, 20 Apr 2022 17:26:08 +0800</pubDate>
</item>
<atom:link href="https://sspai.com/feed" type="application/rss+xml" ref="self"/>
<atom:link href="https://sspai.com/feed" type="application/rss+xml" ref="hub"/>
</channel>
</rss>
|
文档中的第一行:XML 声明 - 定义了文档中使用的 XML 版本和字符编码。此例子遵守 1.0 规范,并使用UTF-8字符集。 下一行是标识此文档是一个 RSS 文档的 RSS 声明(此例是 RSS version 2.0)。 下一行含有 元素。此元素用于描述 RSS订阅源。
元素有三个必需的子元素:
1
2
3
| <title> </title>: 定义频道的标题。(比如 w3school 首页)
<link> : 定义到达频道的超链接。(比如 www.w3school.com.cn)
<description> : 描述此频道(比如免费的网站建设教程)
|
每个 元素可拥有一个或多个 - 元素。
- 元素拥有三个必需的子元素:
1
2
3
| <title> : 定义信息流条目的标题。
<link> : 定义定义信息流条目到达详情页的超链接。
<description> : 定义定义信息流条目的描述信息。
|
最后,后面的两行关闭 和 元素。
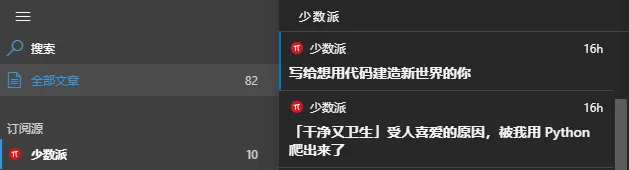
对应Rss阅读器里面的内容如下:
通过上面的小节了解到Rss订阅源就是固定格式的XML文件,放在文件服务器上,Rss阅读器通过网络访问XML文件然后进行解析就可以获取到信息流了。我们要将一个网页里面的内容转换成固定格式的XML文件,需要以下几个步骤:
- 通过HTTP爬取源网站的内容。
- 对源网站的内容数据进行清洗,获得我们想要的数据。
- 将获取的数据组织成Rss固定文件格式,并且生成XML文件。
- 将生成好的Rss订阅源文件放置到静态服务器中。
- 服务器定时重复上面的步骤爬取最新的数据生成新的订阅源进行更行。
- Rss阅读器通过静态服务器链接访问Rss订阅源。
1.爬取源网站的内容
使用requests访问页面,获取Html数据:
1
2
3
4
5
6
7
8
9
10
| import requests
#请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36\
(KHTML, like Gecko) Chrome/75.0.3770.142 Mobile Safari/537.36',
'Content-Type': 'text/html; charset=utf-8',
}
hostUrl='https://sspai.com/'
#模拟请求获取网络数据
html=requests.get(hostUrl,headers=headers)
|
2.对数据进行清洗
使用BeautifulSoup对html网页数据进行清洗,获取我们所需要的数据:
1
2
3
4
5
6
7
8
| from bs4 import BeautifulSoup
bs = BeautifulSoup(html.text,'html.parser')
contents=bs.findAll(class_='advertisementCardBox article')
for content in contents:
title=content.find(class_='title text_ellipsis2').string
url=hostUrl+content.find(class_='pc_card')['href']
detialHtml=requests.get(url,headers=headers)
detial=detialHtml.text
|
对清洗完的数据进行组装,组装成RSS数据,这里又两种方式可以实现一种是通过字符串拼接:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| def createRSS(channel):
rss_text = r'<rss ' \
r' xmlns:atom="http://www.w3.org/2005/Atom" ' \
r' xmlns:itunes="http://www.itunes.com/dtds/podcast-1.0.dtd" ' \
r' version="2.0" ' \
r' encoding="UTF-8"> ' \
r' <channel>' \
r' <title>{}</title>' \
r' <itunes:author>{}</itunes:author>' \
r' <itunes:image href="{}"/>' \
.format(channel.title, channel.author, channel.image)
for item in items:
rss_text += r' <item>' \
r' <title>{}</title>' \
r' <description><![CDATA[{}]]></description>' \
r' <enclosure url="{}" type="audio/mpeg"/>' \
r' </item>'\
.format(item.title, item.description, item.enclosure)
rss_text += r' </channel></rss>'
print(rss_text)
#写入文件
with open(mainUrl.split('/')[-2]+'.xml', 'w' ,encoding='utf-8') as f:
f.write(rss_text)
|
当然手动拼接字符串虽然可以实现效果,但是却极易出现错误,而且也不够灵活,因此我们可以借助PyRSS2Gen这个库来完成Rss数据格式的组装。 如果没有安装PyRSS2Gen的先用Pip进行安装:
组装数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| rssItems=[]
for content in contents:
title=content.find(class_='title text_ellipsis2').string
link=hostUrl+content.find(class_='pc_card')['href']
detialHtml=requests.get(link,headers=headers)
bsDetial = BeautifulSoup(detialHtml.text,'html.parser')
description=bsDetial.prettify()
rssItem=PyRSS2Gen.RSSItem(
title=title,
link=link,
description = str(description),
#时间需要根据网站发布信息的时间单独计算然后格式化
#pubDate =datetime.datetime.now()
)
rssItems.append(rssItem)
rss = PyRSS2Gen.RSS2(
title = "少数派",
link = hostUrl,
description = "少数派致力于更好地运用数字产品或科学方法,帮助用户提升工作效率和生活品质",
lastBuildDate = datetime.datetime.now(),
items = rssItems)
rss.write_xml(open('SSP_Rss.xml', "w",encoding='utf-8'),encoding='utf-8')
|
4.完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| import requests
from bs4 import BeautifulSoup
from lxml import etree
import PyRSS2Gen
import datetime
#请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36\
(KHTML, like Gecko) Chrome/75.0.3770.142 Mobile Safari/537.36',
'Content-Type': 'text/html; charset=utf-8',
}
hostUrl='https://sspai.com'
# 少数派内容爬取
def shaoShuPaiSpider():
#模拟请求获取网络数据
html=requests.get(hostUrl+'/',headers=headers)
#使用BeautifulSoup进行解析
bs = BeautifulSoup(html.text,'html.parser')
contents=bs.findAll(class_='advertisementCardBox article')
rssItems=[]
for content in contents:
title=content.find(class_='title text_ellipsis2').string
link=hostUrl+content.find(class_='pc_card')['href']
detialHtml=requests.get(link,headers=headers)
bsDetial = BeautifulSoup(detialHtml.text,'html.parser')
description=bsDetial.prettify()
rssItem=PyRSS2Gen.RSSItem(
title=title,
link=link,
description = str(description),
#时间需要根据网站发布信息的时间单独计算然后格式化
#pubDate =datetime.datetime.now()
)
rssItems.append(rssItem)
return rssItems
def makeRss(rssItems):
rss = PyRSS2Gen.RSS2(
title = "少数派",
link = hostUrl,
description = "少数派致力于更好地运用数字产品或科学方法,帮助用户提升工作效率和生活品质",
lastBuildDate = datetime.datetime.now(),
items = rssItems)
rss.write_xml(open('SSP_Rss.xml', "w",encoding='utf-8'),encoding='utf-8')
pass
if __name__ == '__main__':
rssItems=shaoShuPaiSpider()
makeRss(rssItems)
|
这里我们使用nodeJs创建一台简单的静态文件服务器:
Nodejs搭建一个的本地静态文件服务器
第一步:在Nodejs安装目录安装:
第二步:在Nodejs安装目录安装:
1
| npm install serve-static
|
第三步:新建server.js (可以放在项目里去运行也可以放在Nodejs安装目录下运行):
1
| var connect = require("connect");var serveStatic = require("serve-static"); var app = connect();app.use(serveStatic("D:\rss")); app.listen(5000);
|
第四步:
上文启动了一台静态服务器,通过服务器访问Rss文件:
1
| http://127.0.0.1:5000/SSP_Rss.xml
|
可以看到数据和官方生成的是一样的,将Rss链接导入Rss阅读器中即可。
通过上面的步骤已经可以生成一个Rss订阅源了,但是这个订阅源生成以后,我们需要每次手动执行python脚本才会爬取网页数据生成新的Rss内容。因此我们需要再定一个任务不断重复执行来保证Python脚本保证Rss数据的更新,由于笔者的Python脚本是跑在Linux上面的,在Linux系统上面执行周期性的任务一般有如下几种方式:
- linux操作系统自带的软件:crontab
- 第三方的定时任务软件:atd、anacron
- WEB定时软件:PPGo_Job
- 基于etcd的定时任务系统
为了简单起见我们就使用Linux系统会自带的crontab来执行周期性定时任务。
1.检查定时服务是否开启
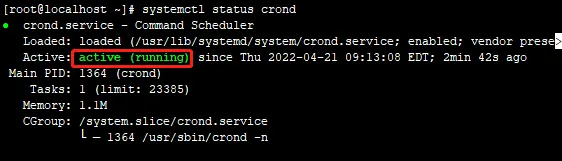
首先确认crond服务是否开启,执行命令:
如果出现如下结果,就表示crond任务已经开启。
crond任务保存的地方在:
1
| /var/spool/cron 所有的用户定时任务都保存在 /var/spool/cron 目录中,当用户增加定时任务时,会在该目录中添加以自己名称命名的文件,并将定时任务保存在其中。
|
定时任务的日志在:
1
2
| /var/log/cron : 可以查看到执行那些定时任务
/var/log/messages: 记录系统操作的日志,(例如:用户登录)
|
当定时任务出现错误的时候,需要排查错误,就需要到定时任务日志文件中去查询错误的原因。
crontab服务操作相关命令:
1
2
3
4
5
| systemctl start crond //启动服务
systemctl stop crond //关闭服务
systemctl restart crond //重启服务
systemctl reload crond //重新载入配置
systemctl status crond //查看状态
|
2.定时任务编写
1
2
| crontab -e : 编辑定时任务(用户可以省略,默认是当前用户)
crontab -l : 查看定时任务(只查看当前用户的定时任务)
|
创建定时任务需要遵循一定的规范, 在crond文件中,前面的五列都代表一个时间,从左到右分别是分钟、小时、天、月、星期,如果不做设置,可以用*跳过,最后一列表示要执行的任务,例如每一分钟执行一次hello.py脚本:
1
| * * * * * python hello.py
|
- “*”代表取值范围内的数字 例如month字段如果是星号,则表示每月都执行该命令操作。
- “/”代表每,可以指定时间的间隔频率,例如“0-23/2”表示每两小时执行一次。同时正斜线可以和星号一起使用,例如*/10,如果用在minute字段,表示每十分钟执行一次。
- “-”代表从某个数字到某个数字 例如“2-6”表示“2,3,4,5,6”。
- “,”分开几个离散的数字 例如,“1,3,5,7,9”。
要求每分钟执行一次:
要求每天的凌晨3点执行一次:
要求每天上午7,9,12点各执行一次:
表示每隔3小时执行:
每个月2号的3点或者每周三的3点执行:
我这里是每一小时以root用户执行一次位于/home/peng/rss的ssp.py脚本生成Rss订阅源:
1
| */60 * * * * root python /home/peng/rss/ssp.py
|