一文搞懂数据转换之摘要、编码、加密、签名
一.转义
转义的作用?
转义通常有两种功能。第一种是如果不进行转义就可能与语法规定的某些内容产生混淆,所以这些内容都被设计为需要转义。 第二种也叫字符引用,用于表示无法在当前上下文中被键盘录入的字符(如字符串中的回车符)。
第一种作用
以经典的JAVA语言中字符串中的字符转义为例。如果在一个字符串中存在一个”符号,那么就需要在”符号前添加\才能够正常的表示,比如下面这样:
1 | String content="他说\"他需要休息\""; |
之所以需要这样,是因为对于字符串来说,”本身就是表示一个字符串的起止符号。如果不进行转义,那么编译器将无法正确的识别其中的”哪些是分隔符,哪些是字符串内部的”。
第二种作用
回车符和换行符,再正常情况下,这样的字符是不可见的,对于这种字符,不过不采用转义的形式进行表达那么会比较困难。如果在一个字符串中存在回车符,那么就需要用\r表示。如果在一个字符串中存在换行符,那么就需要用\n表示。比如下面这样:
1 | String content="床前明月光,/r/n疑是地上霜"; |
二.编码解码
1. 什么是编码解码?
编码本质上采用一种新的载体来表示前一个载体所表达的信息。解码,是编码的逆过程。从概念上可以看出,编码本质上是信息形式的转化,没有保密的作用,因为编码和解码的算法是公开的,只要知道是什么编码的内容,任何人都可以轻松地解码。编码的目的不是为了加密信息,而是将信息转化成统一的格式,方便在不同系统之中传输。
信息->编码->二进制->解码->信息
2. 常见的编码方式
文本文件编码
将“文本数据”编码为“二进制数据”,以实现通过“二进制数据”进行存储或者传输的目的。文本文件在计算机中,最终的载体只能是二进制文件的形式存在。由于计算机诞生在美国,文本内容也只包含有英文内容。因此当时只要使用ASCII进行编码就可以了。但是后来随着计算机的普及,需要表达的信息越来越多了。因此诞生了UTF-8, UTF-16,UTF-32, Unicode, ISO8859-1, GBK, GB2312等等编码形式。在计算机领域,数据存储单位叫字节——byte,最小的存储单元的容量是1位-1bit。一个bit有两个状态 0 和 1。1byte = 8bit。通常,一个英文字母占1字节,汉字采用GBK编码时,占用2字节。UTF-8是可变长度编码,一般用 0-4 字节表示。
但不论如何,这些编码其实都是对文本信息的编码形式。
Base64编码
将“二进制数据”编码为“64个可打印字符的组合”,以实现通过“可打印字符的形式”进行存储或者传输的目的。公钥证书也好,电子邮件数据也好,经常要用到Base64编码,那么为什么要作一下这样的编码呢?因为在计算机中任何数据都是按ascii码存储的,而ascii码的128~255之间的值是不可见字符。 而在网络上交换数据时,比如说从A地传到B地,往往要经过多个路由设备, 由于不同的设备对字符的处理方式有一些不同,这样那些不可见字符就有可能被处理错误,这是不利于传输的。 所以就先把数据先做一个Base64编码,统统变成可见字符,这样出错的可能性就大降低了。
使用场景:
- 在Web场景中,在有些地方限制了数据传输的方式。例如,在URL,只能传递文本。因此,如果想要传输一组二进制数据(例如图片)。那么可以选用Base64编码,将二进制数据编码为可打印的字符串。这样才能完成URL上二进制数据的传输。
- 对证书来说,特别是根证书,一般都是作Base64编码的,因为它要在网上被许多人下载。
- 电子邮件的附件一般也作Base64编码的,因为一个附件数据往往是有不可见字符的。 比如http协议当中的key value字段的值,必须进行URLEncode , 因为一些特殊符号(等号或者空格)是有特殊含义的,造成混淆,解析失败,那么需要把这些值统一处理为可见字符,传输完再解析回来。
URL编码
Url编码的原则就是使用安全的字符(没有特殊用途或者特殊意义的可打印字符)去表示那些不安全的字符从而达到适合传输的目的。由于url只能使用英文字母、数字和某些标点符号,不能使用其他文字和符号,如果需要在URL中传递中文作为参数,或者需要在URL中传递空格、&、?、=等等特殊符号。这个时候就需要进行URL编码。编码的目的HTTP协议的内在要求,通过这种形式,可以浏览器表单数据的打包。
3. 乱码
一般,如果解码之后无法正确还原原来所表达的信息,此时就出现了乱码。例如,使用GB2312的方式去解码一个UTF8编码的文件,那么就会出现乱码。总的来说,乱码通常来说只是因为选用的解码方式和编码方式不同,而导致信息失真的情况。选用正确的编码就能够解读出正确的信息。
在编码或解码时,重点放在所有具有相同算法的人身上,并且该算法通常具有良好的文档记录、广泛的分布和相当容易实现的特点。任何人最终都能解码编码数据。
三.摘要(哈希)
1.什么是摘要
摘要的目的是为了校验信息的完整性,保证信息在传输过程中不被篡改。例如我们下载该压缩包后可以查看压缩包的MD5值。对比下载的压缩包MD5值和网站提供的MD5值,如果两个MD5值不一致,那么说明该压缩包不是官方提供的那个压缩包,可能被替换成其他文件或被修改过。摘要只是用于验证数据完整性和唯一性的哈希值,不管原始数据是什么样的,得到的哈希值都是固定长度的。不管原始数据是什么样的,得到的哈希值都是固定长度的,也就是说摘要并不是原始数据加密后的密文,只是一个验证身份的令牌。所以我们无法通过摘要解密得到原始数据。
2. 哈希算法
散列函数(也叫哈希函数,哈希函数又称散列函数,杂凑函数,他是一个单向密码体制,即从明文到密文的不可逆映射,只有加密过程没有解密过程,哈希函数可以将任意长度的输入经过变化后得到固定长度的输出,这个固定长度的输出称为原消息的散列或消息映射。 理想的哈希函数可以针对不同的输入得到不同的输出,如果存在两个不同的消息得到了相同的哈希值,那我们称这是一个哈希碰撞),如果使用的是hash算法,在计算过程中原文的部分信息是丢失了的,所以不可逆。hash算法的目的:同样的一段数据通过hash函数总是得到相同的摘要,不同的数据通过md5总是应该得到不同的摘要.hash的目的是理想化的,不管什么hash算法实际上总有特别小的概率会出现不同的原始数据通过hash函数可能会得到相同的结果,所以:越好的hash算法会将这个概率降到越低这个概率越低,黑客要通过手段碰撞出相同摘要的难度就越大.常见的算法有md5, sha系列。
MD5
哈希算法,即 hash,又叫散列算法,是一类把任意数据转换为定长(或限制长度)数据的算法统称。哈希算法通常用于制作数字指纹,数字指纹的意思就是「你看到这个东西就像看到原数据一样」,例如我们在一些网站下载大文件的时候,网站提供给我们验证文件完整性的 MD5 或者 SHA1 码,就是原文件的哈希值。优秀的哈希算法通常需要具有低碰撞概率(即不同数据的哈希值通常也不一样)。
加密算法的目的,在于别人无法成功查看加密后的数据,并且在需要的时候还可以对数据进行解密来重新查看数据。而 MD5 算法是一种哈希算法,哈希算法的设计目标本身就决定了,它在大多数时候都是不可逆的,即你经过哈希算法得出的数据,无法再经过任何算法还原回去。所以,既然不能将数据还原,也就不能称之为可以解密;既然不能解密,那么哈希的过程自然也就不能称作是「加密」了。
使用场景
出于这种特性,MD5常用来校验密码是否正确、校验下载文件是否完整无损。
- 校验密码是否正确:将用户注册的密码MD5摘要后储存起来,待用户登录时将用户录入的密码MD5摘要,对比两次摘要后的信息是否相等,相等即密码正确。(一般会进行加盐处理)
- 校验下载文件是否完整无损:我们常下载开源文件资源包时,可以看到网站上提供的该资源包的MD5,下载文件完毕后,可通过自己的程序或直接去一些网站上计算其MD5码,如果与官网上提供的一致,则表示文件完整无损。
SHA系列
sha系列有SHA2、SHA256、SHA512等,这些算法的复杂度相对要高。
3. 破解
MD5本质上不可逆,即不存在逆算法。MD5计算的过程中丢失了信息,一个MD5的值可以对应多个原文。一个MD5理论上的确是可能对应无数多个原文的,因为MD5是有限多个的而原文可以是无数多个。比如主流使用的MD5将任意长度的“字节串映射为一个128bit的大整数。也就是一共有2^128种可能,大概是3.4*10^38,这个数字是有限多个的,而但是世界上可以被用来加密的原文则会有无数的可能性。虽然MD5本质上不可逆但是大部分简单的字符串 通过MD5加密的话 某种程度上来说是”可逆”的。原因是因为很多简单字符串MD5计算后的值,实际上是可以通过查询等方式 得到MD5前的原始串。也就是说只能碰撞,无法真正破解。因为大量信息在hash过程中损失掉了。常用的密码攻击方式 常用的密码攻击方式有字典攻击、暴力破解、查表法、反向查表法、彩虹表等。
- 暴力破解:按照一定的顺序一个一个的去试
- 字典攻击:把常用的密码做成字典,破解时先看字典里是否存在,有效加快破解速度
- 查表法:使用一个大型字典,把每个p和对应的q都记录下来,按q做一下索引,直接查找匹配。
- 彩虹表 :对于HASH的传统做法是把H(X)的所有输出穷举,查找,得出。而彩虹表则是使用散列链的方式进行。
说明: “散列链”是为了降低传统做法空间要求的技术,想法是定义一个衰减函数 R 把散列值变换成另一字符串。通过交替运算H函数和R函数,形成交替的密码和散列值链条。
4. 加盐(salt)
123456的MD5码为e10adc3949ba59abbe56e057f20f883e。一般来说,MD5摘要的结果是128位的摘要信息,然后每4位用一个16进制字符表示,所以,MD5摘要的结果一般显示为32位的16进制。如果你的系统用MD5摘要,并且无加盐,还经常使用123456为测试密码,对这一串MD5码一定很熟悉。这一些MD5码就静静地躺在DB中待校验。如果数据库被暴露(比如拖库),坏人得到了这些MD5码,就可以通过常用密码与其MD5码的映射关系,轻而易举地翻译出大多数密码。所以,一般来说,我们需要对原始密码进行加盐,所谓加盐,就是按照一定规则扰乱原有字符串,然后再进行MD5摘要。这个规则,自己定义,并且一定保密。
为了防止被暴力破解,可以加个密码盐,这样的话暴力破解几乎是搞不定了,即使搞定了可能也因为过去太久时间而变的没有价值。
四.加密解密
1. 加密的概念
数据加密 的基本过程,就是对原来为 明文 的文件或数据按 某种算法 进行处理,使其成为 不可读 的一段代码,通常称为 “密文”。通过这样的途径,来达到保护数据不被非法人窃取、阅读的目的。
对数据进行转换以后,数据变成了另一种格式,并且除了拿到解密方法的人,没人能把数据转换回来。维护数据机密性,即确保数据不会被预期收件人以外的任何人使用。
例如你想给某人发送一封密信,或通过互联网给人发送密码,这些对隐秘性要求比较强的事情,就需要对信息进行加密。
加密的本质是按照一定的算法,将需要表达的信息进行处理,以达到除了信息的发送者和接收者之外,其他人无法识别信息真实内容的目的。
因此,加密通常用于网络通信。因为网络上的通信数据,任何人都有可能会拿到,把数据加密后再传送,送达以后由对方解密后再查看,就可以防止网络上的偷窥。
加密是可逆的,明文 + 秘钥 = 加密信息,加密信息能通过密钥被还原为原始信息。
2. 解密
加密 的 逆过程 为 解密,即将该 编码信息 转化为其 原来数据 的过程。
3. 加密的种类
加密又分为对称加密和非对称加密,区别在于在加密和解密信息时秘钥是不是同一个。若加解密使用相同密钥,则称为对称密钥加密,否则称为非对称密钥加密。
4. 对称加密
对称加密算法 是应用较早的加密算法,又称为 共享密钥加密算法。在 对称加密算法 中,使用的密钥只有一个,发送 和 接收 双方都使用这个密钥对数据进行 加密 和 解密。这就要求加密和解密方事先都必须知道加密的密钥。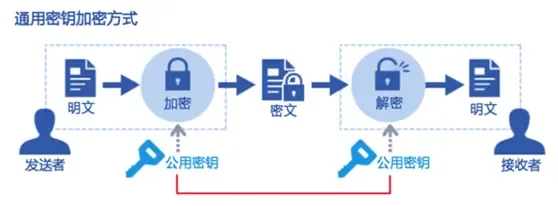
数据加密过程:在对称加密算法中,数据发送方 将 明文 (原始数据) 和 加密密钥 一起经过特殊 加密处理,生成复杂的 加密密文 进行发送。
数据解密过程:数据接收方 收到密文后,若想读取原数据,则需要使用 加密使用的密钥 及相同算法的 逆算法 对加密的密文进行解密,才能使其恢复成 可读明文。
对称加密算法的特点是算法公开、计算量小、加密速度快、加密效率高。对称加密有很多种算法,由于它效率很高,所以被广泛使用在很多加密协议的核心当中。
不足之处是,交易双方都使用同样钥匙,安全性得不到保证。
常见的对称加密有DES,3DES,AES,Blowfish,Twofish,IDEA,RC6,CAST5 等。
DES加密
Data Encryption Standard,数据加密标准,速度较快,适用于加密大量数据的场合。
DES 加密算法出自 IBM 的研究,后来被美国政府正式采用,之后开始广泛流传。
但近些年使用越来越少,因为 DES 使用 56 位密钥,以现代的计算能力,24 小时内即可被破解。
AES加密
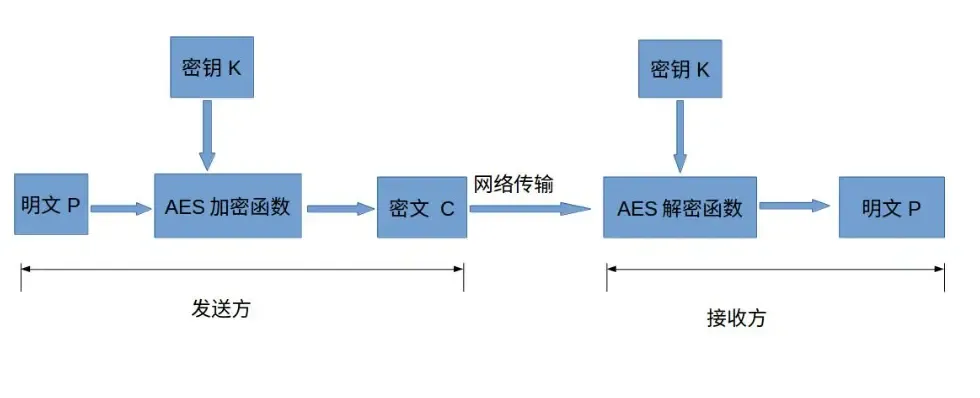
AES的全称是Advanced Encryption Standard,意思是高级加密标准。它的出现主要是为了取代DES加密算法的,
因为我们都知道DES算法的密钥长度是56Bit,因此算法的理论安全强度是2的56次方。比较容易被破解。
而AES可以使用128、192、和256位密钥,并且用128位分组加密和解密数据,相对来说安全很多。
。完善的加密算法在理论上是无法破解的,除非使用穷尽法。使用穷尽法破解密钥长度在128位以上的加密数据是不现实的,
仅存在理论上的可能性。统计显示,即使使用目前世界上运算速度最快的计算机,穷尽128位密钥也要花上几十亿年的时间,
更不用说去破解采用256位密钥长度的AES算法了。
AES为分组密码,分组密码也就是把明文分成一组一组的,每组长度相等,每次加密一组数据,直到加密完整个明文。
在AES标准规范中,分组长度只能是128位,也就是说,每个分组为16个字节(每个字节8位)。密钥的长度可以使用128位、192位或256位。
- 填充:
要想了解填充的概念,我们先要了解AES的分组加密特性。
什么是分组加密呢?我们来看看下面这张图:
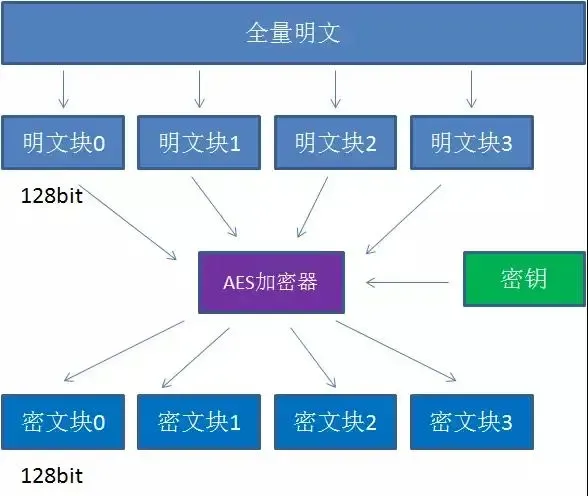
AES算法在对明文加密的时候,并不是把整个明文整个加密成一整段密文,而是把明文拆分成一个个独立的明文块,每一个明文块长度128bit。
这些明文块经过AES加密器的复杂处理,生成一个个独立的密文块,这些密文块拼接在一起,就是最终的AES加密结果。
但是这里涉及到一个问题:假如一段明文长度是192bit,如果按每128bit一个明文块来拆分的话,第二个明文块只有64bit,不足128bit。这时候怎么办呢?就需要对明文块进行填充(Padding)。
AES在不同的语言实现中有许多不同的填充算法,我们只举出集中典型的填充来介绍一下。
NoPadding:
不做任何填充,但是要求明文必须是16字节的整数倍。PKCS5Padding(默认):
如果明文块少于16个字节(128bit),在明文块末尾补足相应数量的字符,且每个字节的值等于缺少的字符数。ISO10126Padding:
如果明文块少于16个字节(128bit),在明文块末尾补足相应数量的字节,最后一个字符值等于缺少的字符数,其他字符填充随机数。
需要注意的是,如果在AES加密的时候使用了某一种填充方式,解密的时候也必须采用同样的填充方式。
- 模式:
AES的工作模式,体现在把明文块加密成密文块的处理过程中。AES加密算法提供了五种不同的工作模式:ECB、CBC、CTR、CFB、OFB
模式之间的主题思想是近似的,在处理细节上有一些差别。我们这一期只介绍各个模式的基本定义。
- ECB模式(默认):电码本模式
- CBC模式:密码分组链接模式
- CTR模式:计算器模式
- CFB模式:密码反馈模式
- OFB模式:输出反馈模式
同样的,如果在AES加密的时候使用了某一种工作模式,解密的时候也必须采用同样的工作模式。
填充明文时,如果明文长度原本就是16字节的整数倍,那么除了NoPadding以外,其他的填充方式都会填充一组额外的16字节明文块。
5. 非对称加密
非对称加密算法,又称为公开密钥加密算法。它需要两个密钥,一个称为 公开密钥 (public key),即 公钥,另一个称为 私有密钥 (private key),即 私钥。
因为 加密 和 解密 使用的是两个不同的密钥,所以这种算法称为 非对称加密算法。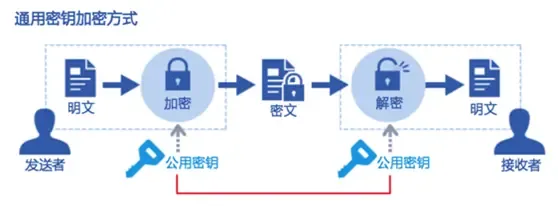
如果使用 公钥 对数据 进行加密,只有用对应的 私钥 才能 进行解密。
如果使用 私钥 对数据 进行加密,只有用对应的 公钥 才能 进行解密。
密钥是成对出现。使用一对“私钥-公钥”,用私钥加密的内容只有对应公钥才能解开
常见的非对称加密有 RSA、ESA、ECC 等。
RSA加密
RSA名称来源于发明这个算法的三个人的姓氏组成,算法大致内容就是对极大整数进行因式分解。
这种算法非常可靠,密钥越长,它就越难破解。根据已经披露的文献,目前被破解的最长 RSA密钥是768个二进制位。
也就是说,长度超过768位的密钥,还无法破解(至少没人公开宣布)。因此可以认为,1024位的RSA密钥基本安全,2048位的密钥极其安全。
目前主流的有 RSA-1024, RSA-2048,RSA-4096等,数字代表的是密钥长度,密钥长度越长,安全性越高,但相应的性能会下降。
RSA算法优点
- 不需要进行密钥传递,提高了安全性
- 可以进行数字签名认证
RSA算法缺点
- 加密解密效率不高,一般只适用于处理小量数据(如:密钥)
- 容易遭受小指数攻击
RSA算法提供了生成公钥和私钥的方法,注意是成对生成的!一般将公钥保存在客户端、私钥保存在服务端。黑客反编译可能拿到公钥,但是因为私钥存储在服务器,所以不用太担心泄密。
RSA加解密中必须考虑到的密钥长度、明文长度和密文长度的问题。明文长度需要小于密钥长度,而密文长度则等于密钥长度。因此当加密内容长度大于密钥长度时,有效的RSA加解密就需要对内容进行分段。
这是因为,RSA算法本身要求加密内容也就是明文长度m必须0<m<密钥长度n。如果小于这个长度就需要进行padding,因为如果没有padding,就无法确定解密后内容的真实长度,字符串之类的内容问题还不大,
以0作为结束符,但对二进制数据就很难,因为不确定后面的0是内容还是内容结束符。而只要用到padding,那么就要占用实际的明文长度,于是实际明文长度需要减去padding字节长度。密钥默认是1024位,
即1024位/8位-11=128-11=117字节。所以默认加密前的明文最大长度117字节,解密密文最大长度为128字。两者相差11字节是因为RSA加密使用到了填充模式(padding),即内容不足117字节时会自动填满,
用到填充模式自然会占用一定的字节,而且这部分字节也是参与加密的。我们一般使用的padding标准有NoPPadding、OAEPPadding、PKCS1Padding等。
如果加密的数据不是分组大小的整数倍,则会根据具体的应用方式增加额外的填充位。
RSA加密中的Padding
严格地说RSA也是一种“块”加密/解密。加密前输入长度必须与“模”相同:不足需要补足(Padding);输入长度大于“模”长度,则需要“分组”,最后一组同样需要Padding。
因此模的长度也大于加密明文的长度,因此RSA不适合加密大段文本,一般用来加密一个对称加密的密钥,然后再用此对称加密密钥对大段文本加密。
- RSA_PKCS1_PADDING 填充模式,
最常用的模式,当你选择 RSA_PKCS1_PADDING 填充模式时,如果你的明文不够 128 字节, 加密的时候会在你的明文中随机填充一些数据,
所以会导致对同样的明文每次加密后的结果都不一样。对加密后的密文,服务器使用相同的填充方式都能解密。解密后的明文也就是之前加密的明文。
输入:必须 比 RSA 钥模长(modulus) 短至少11个字节, 也就是 RSA_size(rsa) – 11 如果输入的明文过长,必须切割,然后填充。
输出:和modulus一样长。
根据这个要求,对于512bit的密钥, block length = 512/8 – 11 = 53 字节
- for RSA_NO_PADDING不填充模式,
当在客户端选择 RSA_NO_PADDING 填充模式时,如果你的明文不够 128 字节, 加密的时候会在你的明文前面,前向的填充零。
解密后的明文也会包括前面填充的零,这是服务器需要注意把解密后的字段前向填充的零去掉,才是真正之前加密的明文。
输入:可以和RSA钥模长一样长,如果输入的明文过长,必须切割, 然后填充
输出:和modulus一样长
- RSA_PKCS1_OAEP_PADDING填充模式,
是 PKCS#1 推出的新的填充方式,安全性是最高的,和前面 RSA_PKCS1_PADDING 的区别就是加密前的编码方式不一样
- 输入:RSA_size(rsa) – 41
- 输出:和modulus一样长
不同的填充方式加解密也是不同的,使用的时候要注意
五.数字签名和验签
1. 数字签名的原理是?
A:数字签名技术是将明文进行特定HASH函数得到的摘要信息(消息完整性),再将摘要信息用A的私钥加密(身份认证),得到数字签名,将密文和数字签名一块发给B。
B:收到A的消息后,先将密文用自己的私钥解密,得到明文。将数字签名用A的公钥进行解密后,得到正确的摘要(解密成功说明A的身份被认证了)。
对明文进行摘要运算,得到实际收到的摘要,将两份摘要进行对比,如果一致,说明消息没有被篡改(消息完整性)。
2. 数字签名的作用是?
- 一是能确定消息的不可抵赖性,因为他人假冒不了发送方的私钥签名。发送方是用自己的私钥对信息进行加密的,只有使用发送方的公钥才能解密。
- 二是数字签名能保障消息的完整性。一次数字签名采用一个特定的哈希函数,它对不同文件产生的数字摘要的值也是不相同的。